From Biostatistics to AI: A Gentle Bridge for Beginners
 Terminology Notes with Examples and References
Terminology Notes with Examples and References
Based on the uploaded lecture transcript “From Biostatistics to AI: A Gentle Bridge for Beginners.”
1. Physician Above the Tool
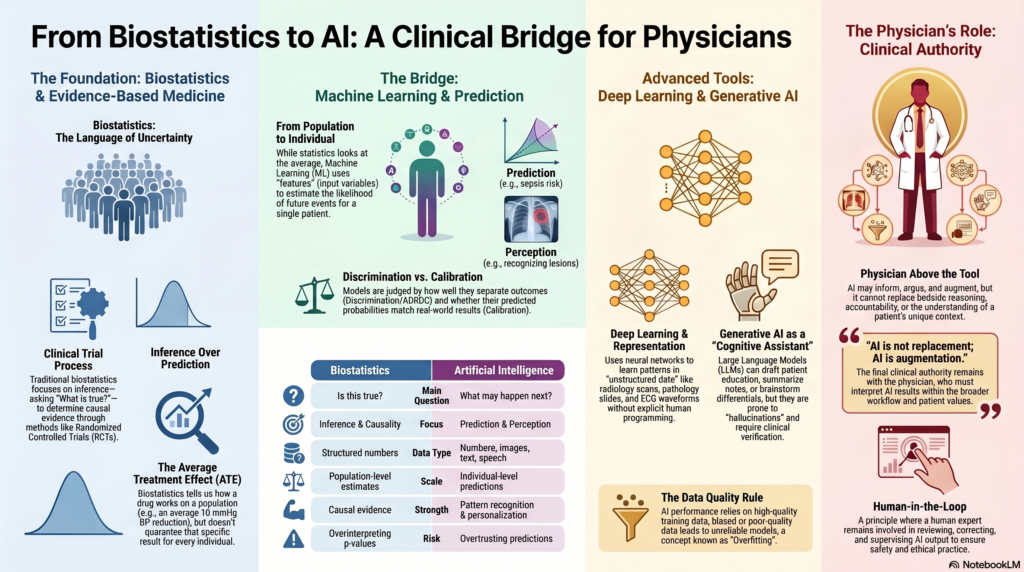
The central idea of the lecture is that the physician remains above the tool. Biostatistics, machine learning, deep learning, and generative AI are all instruments. They can support medical reasoning, but they cannot replace the physician’s responsibility.
The lecture begins by reminding us that medicine is not merely about identifying the disease. It is about understanding the person who has the disease.
Clinical example:
Two patients may both have diabetes. One may be a young professional with obesity and poor sleep. Another may be an elderly patient with frailty, renal impairment, and polypharmacy. The disease name is the same, but the clinical decision-making is different.
Key point:
AI may inform, argue, accelerate, and augment. But it cannot replace bedside reasoning, clinical judgement, or accountability.
2. Biostatistics
Biostatistics is the application of statistical methods to biological, medical, and public health data.
It helps doctors answer questions such as:
- Does this treatment work?
- How large is the benefit?
- Is the result real or due to chance?
- Can the result be applied to my patient?
- How confident are we about the estimate?
Clinical example:
A trial compares Drug A with placebo for hypertension. Biostatistics helps determine whether Drug A reduces blood pressure more than placebo, whether the difference is statistically significant, and how precise the estimate is.
Role in medicine:
Biostatistics is the traditional language of evidence-based medicine. It gives medicine a disciplined way of handling uncertainty.
3. Evidence-Based Medicine
Evidence-Based Medicine (EBM) means using the best available scientific evidence, clinical expertise, and patient values to make decisions.
Biostatistics supports EBM by helping doctors interpret trials, observational studies, diagnostic tests, and systematic reviews.
Example:
A randomised controlled trial may show that a new anticoagulant reduces stroke risk compared with warfarin. The clinician then decides whether that evidence applies to an elderly patient with renal impairment and high bleeding risk.
Key distinction:
Evidence-based medicine often tells us what works on average. AI tries to move closer to what may happen in this particular patient.
4. Causal Evidence
Causal evidence asks whether one factor actually causes an outcome.
It is different from simple association.
Example:
If a drug lowers blood pressure compared with placebo in a well-designed randomised controlled trial, we may infer that the drug caused the blood pressure reduction.
Clinical question:
Does this therapy really improve clinical outcomes?
This is one of the classic questions answered by biostatistics.
5. Association
Association means two variables move together, but one may not necessarily cause the other.
Example:
Low vitamin D levels may be associated with depression. But that does not automatically mean low vitamin D causes depression, or that vitamin D supplementation will treat depression.
Clinical warning:
Association is not causation.
AI models may detect associations very efficiently, but causation still requires stronger study designs and clinical reasoning.
6. Prediction
Prediction estimates the likelihood of a future event.
This is where AI becomes powerful.
Examples:
- Will this patient develop sepsis?
- Will this patient be readmitted?
- Will this patient deteriorate in ICU?
- Will this diabetic patient develop retinopathy?
- Will this patient respond to a particular treatment?
In the lecture, prediction is described as one of the key shifts from classical biostatistics to AI. Biostatistics often focuses on inference, while machine learning focuses strongly on prediction.
7. Inference
Inference means drawing conclusions from data.
In biostatistics, inference asks:
Is this observed effect likely to be real?
Example:
If a study finds that CBT improves insomnia scores, inference helps determine whether the improvement is likely due to CBT rather than random variation.
Difference from prediction:
Inference asks, “What is true?”
Prediction asks, “What is likely to happen?”
8. Average Treatment Effect
The Average Treatment Effect (ATE) refers to the average benefit or harm of a treatment in a study population.
Example:
A drug may reduce systolic blood pressure by an average of 10 mmHg in a clinical trial.
But this does not mean every patient gets a 10 mmHg reduction. Some may improve greatly, some mildly, and some may develop side effects.
Why AI matters:
AI tries to move from average treatment effects to more individualised predictions.
Simple contrast:
| Biostatistics | AI |
|---|---|
| Does it work on average? | Will it work for this patient? |
| Population-level estimate | Individual-level prediction |
| Causal inference | Personalised risk estimation |
9. Effect Size
Effect Size tells us how large the treatment effect is.
A p-value tells us whether the result is statistically unlikely to be due to chance.
Effect size tells us whether the result is clinically meaningful.
Example:
A drug may reduce depression score by 1 point on a scale. This may be statistically significant in a large trial, but clinically unimpressive.
Clinical importance:
Doctors should not ask only:
Is it significant?
They should also ask:
Is it meaningful?
10. Confidence Interval
A Confidence Interval (CI) gives a range within which the true effect is likely to lie.
Example:
A drug reduces systolic blood pressure by 10 mmHg, with a 95% confidence interval of 6 to 14 mmHg.
This means the estimate is reasonably precise.
If the confidence interval were 1 to 19 mmHg, the result would be less precise.
Clinical interpretation:
A narrow confidence interval gives more confidence.
A wide confidence interval means more uncertainty.
11. p-Value
A p-value estimates how likely the observed result would be if there were truly no effect.
Example:
If p < 0.05, researchers often say the result is statistically significant.
Caution:
A p-value does not tell us:
- Whether the effect is large
- Whether the effect is clinically useful
- Whether the study is unbiased
- Whether the result applies to our patient
Clinical point:
p-values must be interpreted along with effect size, confidence interval, study design, and clinical judgement.
12. Generalisability
Generalisability means whether the findings of a study can be applied to patients outside the study sample.
Example:
A trial conducted in young Western patients may not apply directly to elderly Indian patients with multiple comorbidities.
AI relevance:
An AI model trained in one hospital may fail in another hospital if patient population, equipment, workflow, or disease prevalence differs.
13. External Validity
External Validity is closely related to generalisability. It asks whether the results are valid beyond the original study setting.
Example:
A sepsis prediction model developed in a US ICU may not work well in a smaller Indian hospital with different documentation practices and delayed lab reporting.
Clinical question:
Does this evidence apply to my patients, my hospital, and my workflow?
14. Randomised Controlled Trial
A Randomised Controlled Trial (RCT) is a study where participants are randomly assigned to intervention or control groups.
RCTs are powerful because randomisation reduces bias and helps establish causality.
Example:
Patients with hypertension are randomly assigned to Drug A or placebo. If Drug A reduces stroke risk, we can more confidently infer causation.
Why still important in AI era:
Even if AI predicts that a treatment may work, RCTs may still be needed to prove whether using that AI tool improves patient outcomes.
15. Causal Inference
Causal Inference refers to methods used to determine whether one factor causes another.
This becomes important when RCTs are not possible.
Example:
If we want to know whether smoking causes lung cancer, we cannot ethically randomise people to smoke. Instead, we use observational data and causal inference methods.
AI caution:
Machine learning may predict well without explaining causality. A model may identify who is at risk but not why they are at risk.
16. Bayesian Probability
Bayesian Probability updates the probability of a disease based on new evidence.
In clinical medicine, doctors use Bayesian thinking even when they do not explicitly call it that.
Example:
A patient with chest pain has a pre-test probability of myocardial infarction. ECG and troponin results modify that probability.
Clinical version:
Prior probability + new evidence = updated probability.
Diagnostic relevance:
Bayesian thinking is central to interpreting diagnostic tests, likelihood ratios, and changing probability after a test result.
17. Likelihood Ratio
A Likelihood Ratio (LR) tells us how much a test result changes the probability of disease.
Example:
A positive troponin in the right clinical context increases the probability of myocardial infarction.
Types:
- Positive likelihood ratio: how much a positive test increases disease probability
- Negative likelihood ratio: how much a negative test decreases disease probability
Clinical importance:
A test is not interpreted in isolation. It must be interpreted in the context of pre-test probability.
18. Sensitivity
Sensitivity is the ability of a test to correctly identify people who have the disease.
Example:
If a test has high sensitivity for pulmonary embolism, it is good at detecting patients who truly have pulmonary embolism.
Mnemonic:
Sensitive tests are useful for ruling out disease when negative.
19. Specificity
Specificity is the ability of a test to correctly identify people who do not have the disease.
Example:
If a test has high specificity for a disease, a positive result strongly suggests the disease is present.
Mnemonic:
Specific tests are useful for ruling in disease when positive.
20. Machine Learning
Machine Learning (ML) is a branch of AI where models learn patterns from data and make predictions on new data.
Unlike classical statistics, machine learning is often less concerned with explaining causation and more concerned with making accurate predictions.
Medical examples:
- Predicting ICU deterioration
- Predicting hospital readmission
- Predicting sepsis risk
- Predicting length of stay
- Predicting treatment response
Rajkomar, Dean, and Kohane describe machine learning as a major tool for processing complex medical data and supporting prediction in medicine [1].
21. Feature
A Feature is an input variable used by a machine learning model.
Examples of features in a diabetes prediction model:
- Age
- BMI
- HbA1c
- Fasting glucose
- Family history
- Physical activity
- Blood pressure
- Lipid profile
- Sleep pattern
- Medication history
Clinical equivalent:
A feature is like a clinical clue given to the model.
22. Feature Engineering
Feature Engineering means selecting, transforming, or creating useful input variables for a machine learning model.
Example:
Instead of giving the model only a patient’s blood pressure readings, we may create a feature called “blood pressure variability over 30 days.”
Clinical example:
For psychiatric relapse prediction, useful features may include missed appointments, sleep reduction, medication non-adherence, previous admissions, substance use, and family stressors.
23. Training Data
Training Data is the data used to teach the AI model.
Example:
If we want to train a model to detect diabetic retinopathy, we give it thousands of labelled retinal images.
Important point:
If the training data is biased or poor quality, the AI model will also become biased or unreliable.
24. Test Data
Test Data is data not seen by the model during training. It is used to check whether the model performs well on new cases.
Example:
A model trained on retinal images from Hospital A should be tested on retinal images from Hospital B.
Clinical principle:
A model should not be judged only by how well it performs on familiar data.
25. Cross-Validation
Cross-Validation is a method used to test how well a model performs by repeatedly splitting the data into training and testing parts.
Example:
In 5-fold cross-validation, the data is divided into five parts. The model trains on four parts and tests on the remaining part. This process is repeated five times.
Purpose:
It reduces the risk that performance is due to one lucky data split.
26. Overfitting
Overfitting occurs when a model learns the training data too closely, including noise and irrelevant details.
It performs well on training data but poorly on new patients.
Clinical example:
A model trained in one hospital may learn that a particular lab format or scanner artifact predicts disease. When used in another hospital, it fails.
Simple analogy:
A student memorises old exam answers but cannot solve a new question.
27. Underfitting
Underfitting occurs when a model is too simple and fails to capture important patterns.
Example:
Trying to predict suicide risk using only age and gender would likely underfit because the phenomenon is far more complex.
Clinical implication:
An underfit model misses important clinical signals.
28. Bias-Variance Trade-Off
The Bias-Variance Trade-Off describes the balance between a model being too simple and too unstable.
- High bias: model is too simple
- High variance: model is too sensitive to training data
- Good model: balances simplicity and flexibility
Clinical example:
A very simple model may miss high-risk psychiatric relapse. A very complex model may detect patterns that are not real.
Practical message:
More complex is not always better.
29. Calibration
Calibration means whether predicted probabilities match real-world outcomes.
Example:
If an AI model says 100 patients each have a 20% risk of readmission, about 20 of them should actually be readmitted.
Clinical importance:
A poorly calibrated model may appear accurate but mislead decision-making.
30. Discrimination
Discrimination means how well a model separates those who will have an outcome from those who will not.
Example:
Can a sepsis model distinguish patients who will deteriorate from those who will remain stable?
Common metric:
Area under the receiver operating characteristic curve, or AUROC.
31. AUROC
AUROC stands for Area Under the Receiver Operating Characteristic Curve.
It measures how well a model discriminates between two outcomes.
Example:
A model predicting sepsis with an AUROC of 0.90 usually discriminates better than one with an AUROC of 0.65.
Caution:
A high AUROC does not automatically mean the model is clinically useful. Workflow, calibration, safety, and patient benefit still matter.
32. Deep Learning
Deep Learning is a type of machine learning that uses multiple neural network layers to learn complex patterns.
It is especially useful for high-dimensional data such as:
- Images
- Audio
- Video
- Text
- ECG waveforms
- Pathology slides
- Radiology scans
Clinical examples:
- Detecting diabetic retinopathy from retinal images
- Identifying lung nodules on CT
- Detecting skin cancers from photographs
- Reading pathology slides
- Analysing speech patterns
Deep learning became a major force in modern AI because of its strong performance in perception-based tasks such as vision and speech [2].
33. Representation Learning
Representation Learning means the model learns useful internal patterns from raw data.
Example:
A deep learning model looking at a retinal image may learn vessel patterns, microaneurysms, haemorrhages, and exudates without a human explicitly programming each rule.
In simple language:
The model learns how to “represent” the image internally so that it can classify it.
34. Perception
Perception in AI refers to the ability to interpret complex sensory-like data such as images, audio, and text.
In the lecture, perception was distinguished from prediction.
Example of perception:
AI looks at a chest X-ray and recognises a lesion.
Example of prediction:
AI estimates whether this patient is likely to need ICU admission in the next 12 hours.
Simple distinction:
| Term | Meaning | Example |
|---|---|---|
| Perception | Understanding input | Detecting opacity on X-ray |
| Prediction | Estimating future outcome | Risk of ICU transfer |
35. High-Dimensional Data
High-Dimensional Data means data with many variables, layers, or forms.
In medicine, high-dimensional data includes:
- Images
- Voice
- Text
- Genomics
- Wearable data
- EHR data
- Time-series vitals
- Multi-omics data
In the lecture discussion, it was explained that statistics mainly works with structured numbers, whereas AI can work with numbers, text, images, speech, and complex signals.
Clinical example:
A diabetic patient’s risk may be estimated using age, HbA1c, retinal images, glucose trends, medication adherence, physical activity, sleep, and kidney function.
36. Structured Data
Structured Data is organised data that fits neatly into rows and columns.
Examples:
- Age
- Blood pressure
- HbA1c
- Sodium
- Creatinine
- Diagnosis code
- Medication dose
This is the kind of data classical statistics handles well.
37. Unstructured Data
Unstructured Data does not fit neatly into tables.
Examples:
- Doctor’s notes
- Discharge summaries
- Voice recordings
- Radiology images
- Pathology slides
- Patient messages
- Endoscopy videos
AI is useful because it can process unstructured data more effectively than classical statistical methods.
38. Generative AI
Generative AI refers to AI that creates new content.
It can generate:
- Text
- Summaries
- Images
- Code
- Clinical note drafts
- Patient education material
- Differential diagnosis lists
Medical example:
A doctor may ask a generative AI tool to draft a patient-friendly explanation of hypertension.
Caution:
Generative AI predicts plausible text. It does not guarantee truth.
39. Large Language Model
A Large Language Model (LLM) is a generative AI model trained on large amounts of text.
Examples:
ChatGPT, Gemini, Claude, Llama.
Useful for:
- Drafting
- Summarising
- Explaining
- Translating
- Organising notes
- Brainstorming differentials
Important caution from the lecture:
General models such as ChatGPT are not automatically medical models. They reason about healthcare through language unless specifically trained and validated on clinical data.
40. Prompt
A Prompt is the instruction given to a generative AI model.
Example prompt:
“Explain hypertension to a 55-year-old patient in simple language, with diet and exercise advice.”
Clinical use:
Good prompting can improve the clarity of AI output, but prompting cannot replace clinical verification.
41. Prompt Stability
Prompt Stability means whether similar prompts produce consistent and safe answers.
Example:
If a doctor asks the same clinical question in slightly different ways, the AI should not give dangerously different answers.
Clinical relevance:
Unstable AI output is risky in healthcare.
42. Hallucination
Hallucination means AI generates content that sounds confident but is false.
Example:
An AI model may invent a study, misquote a guideline, or suggest a non-standard dose.
Clinical rule:
Generative AI is useful for drafts and ideas, but dangerous when trusted without verification.
43. Cognitive Assistant
A Cognitive Assistant is a tool that helps clinicians think, organise, summarise, and generate possibilities.
The lecture emphasised that chatbots and generative AI tools should be treated as cognitive assistants, not clinical authorities.
Useful for:
- Structuring differential diagnoses
- Summarising evidence
- Drafting notes
- Preparing patient education
- Generating teaching material
Not suitable for unsupervised:
- Final diagnosis
- Final prescription
- Emergency decision-making
- Medico-legal documentation without review
- Patient-specific advice without clinician oversight
44. Clinical Authority
Clinical Authority means the person or system that carries responsibility for diagnosis and treatment.
AI may assist, but the clinician remains the authority.
Example:
AI may suggest that a patient has high sepsis risk. The doctor must examine the patient, interpret the context, and decide management.
Core principle:
AI can assist decision-making, but the doctor remains accountable.
45. Synthetic Data
Synthetic Data is artificially generated data that imitates real data.
Uses:
- Training AI models
- Protecting privacy
- Simulating rare cases
- Testing systems
Caution from the lecture discussion:
Synthetic data can be useful, but in healthcare it must be handled carefully. A model trained on unrealistic synthetic data may become unsafe.
Clinical example:
Synthetic retinal images may be generated for training, but they must be validated against real retinal images.
46. Data Privacy
Data Privacy means protecting patient information from misuse.
The lecture discussion clearly warned that patient data should not be directly entered into public AI tools unless there is an appropriate institutional agreement, privacy protection, or secure deployment.
Patient data includes:
- Text notes
- Images
- Voice
- Reports
- Videos
- Identifiers
- Clinical histories
Practical rule:
Do not upload identifiable patient data into public AI tools.
47. De-Identification
De-Identification means removing personal identifiers from patient data.
Examples of identifiers:
- Name
- Phone number
- Address
- Hospital number
- Face image
- Date of birth
- Unique clinical details that reveal identity
Clinical caution:
De-identification is not always simple. A rare case description may identify a patient even without name or phone number.
48. Model Validation
Model Validation means testing whether an AI model works accurately, safely, and usefully.
For AI in healthcare, validation must ask:
- Does it work on new data?
- Does it work in another hospital?
- Does it work in Indian patients?
- Does it work across devices?
- Does it improve clinical outcomes?
- Does it cause harm through false positives or false negatives?
TRIPOD+AI provides updated reporting guidance for prediction models using regression or machine learning methods [3].
49. External Validation
External Validation means testing the model in a dataset different from the one used to develop it.
Example:
A model trained on data from a tertiary hospital in Bengaluru should be tested in hospitals in Chennai, Delhi, rural settings, and different patient groups before broad adoption.
Why it matters:
A model may perform well in its birthplace but fail elsewhere.
50. Dataset Shift
Dataset Shift occurs when the data used in real practice differs from the data used to train the model.
Examples:
- Different scanner
- Different patient population
- Different disease prevalence
- Different lab method
- Different documentation practice
- Different referral pattern
Clinical implication:
AI performance may deteriorate silently when the environment changes.
51. Model Drift
Model Drift occurs when model performance changes over time.
Example:
A sepsis prediction model may perform well initially but become less accurate after hospital protocols, antibiotic practices, or patient profiles change.
Clinical need:
AI models need continuous monitoring.
52. Explainability
Explainability means understanding why a model produced a particular output.
Example:
If an AI tool says a patient has high risk of readmission, the doctor should know whether the risk is driven by repeated admissions, poor medication adherence, uncontrolled diabetes, low oxygen saturation, or social vulnerability.
Clinical importance:
Explainability supports trust, communication, audit, and medico-legal defensibility.
53. Black Box Model
A Black Box Model gives outputs without clearly explaining the reasoning.
Example:
An AI says “high risk” but does not show what factors led to that conclusion.
Clinical concern:
Black box decisions are difficult to explain to patients and difficult to defend if harm occurs.
54. Automation
Automation means using technology to perform repetitive tasks with minimal human effort.
Medical examples:
- Auto-generating discharge summaries
- Auto-filling structured notes
- Auto-triaging simple queries
- Auto-detecting normal imaging
- Auto-scheduling follow-ups
Clinical benefit:
Automation can reduce clerical burden and improve efficiency.
55. Augmentation
Augmentation means improving human performance rather than replacing it.
Example:
AI may highlight suspicious areas on a scan, but the radiologist makes the final interpretation.
Best framing:
AI is not replacement. AI is augmentation.
56. Clinical Utility
Clinical Utility means whether a tool actually helps patient care.
A model may be statistically impressive but clinically useless.
Example:
A model predicts readmission risk accurately, but if the hospital has no intervention pathway for high-risk patients, the model has limited practical value.
Clinical question:
Does this tool change management in a way that benefits the patient?
57. Workflow Integration
Workflow Integration means fitting the AI tool into real clinical practice.
Example:
A sepsis alert should reach the right nurse or doctor at the right time, in a form that prompts action.
Poor workflow example:
An alert appears in a dashboard no one checks.
Key point:
AI success depends not only on model accuracy but also on clinical workflow.
58. Human-in-the-Loop
Human-in-the-Loop means a human expert remains involved in reviewing, correcting, and supervising AI output.
Example:
AI drafts a discharge summary. The doctor edits, verifies, and signs it.
Why important:
Medicine requires responsibility, context, ethics, and judgement.
59. CONSORT-AI and SPIRIT-AI
CONSORT-AI and SPIRIT-AI are reporting guidelines for clinical trials involving AI interventions.
- CONSORT-AI: reporting completed AI clinical trials
- SPIRIT-AI: writing protocols for AI clinical trials
They improve transparency by requiring clear description of the AI intervention, data inputs, human-AI interaction, and error handling [4].
60. DECIDE-AI
DECIDE-AI is a reporting guideline for early-stage clinical evaluation of AI-based decision support systems.
It is particularly relevant before full-scale randomised trials, when AI tools are being tested in live clinical settings.
DECIDE-AI emphasises reporting of human factors, workflow integration, safety, and real-world clinical performance [5].
Simple Clinical Analogy
| Concept | Biostatistics | AI |
|---|---|---|
| Main question | Is this true? | What may happen next? |
| Focus | Inference | Prediction and perception |
| Data type | Mostly structured numbers | Numbers, images, text, speech, signals |
| Output | Evidence, effect size, uncertainty | Risk score, classification, generated content |
| Strength | Causality and evidence | Pattern recognition and personalisation |
| Risk | Overinterpreting p-values | Overtrusting predictions |
| Doctor’s role | Interpret evidence | Supervise model output |
Diabetes Example: Statistics vs AI
Biostatistics approach
A study may ask:
Does hypertension increase heart attack risk among patients with diabetes?
It may compare diabetic patients with and without hypertension and calculate relative risk, hazard ratio, confidence interval, and p-value.
This gives population-level evidence.
Machine learning approach
A machine learning model may ask:
Given this patient’s age, HbA1c, BP, lipid profile, ECG, renal function, smoking status, family history, and medication adherence, what is the probability of heart attack in the next five years?
This gives individual-level prediction.
Deep learning approach
A deep learning model may analyse retinal images, ECG waveforms, or echocardiographic images to detect subtle patterns linked to diabetic vascular disease.
This adds perception.
Generative AI approach
A generative AI tool may help the doctor explain diabetes risk to the patient in simple language or draft a lifestyle counselling note.
This supports communication, not clinical authority.
Final High-Yield Summary
The lecture teaches that the transition from biostatistics to AI is not a replacement. It is an expansion.
Biostatistics remains essential because it tells us about:
- Evidence
- Causality
- Effect size
- Uncertainty
- Generalisability
AI adds new capabilities:
- Prediction
- Perception
- High-dimensional data analysis
- Personalised risk estimation
- Automation
- Clinical augmentation
The most important message is:
Biostatistics tells us what is true in a population. AI helps us estimate what may happen to this patient. The physician must understand both.
References
- Rajkomar A, Dean J, Kohane I. Machine learning in medicine. New England Journal of Medicine. 2019;380(14):1347-1358.
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436-444.
- Collins GS, Moons KGM, Dhiman P, et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. 2024;385:e078378.
- Liu X, Rivera SC, Moher D, Calvert MJ, Denniston AK. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Nature Medicine. 2020;26(9):1364-1374.
- Vasey B, Nagendran M, Campbell B, et al. Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. Nature Medicine. 2022;28(5):924-933.