Data Foundation of Clinical AI
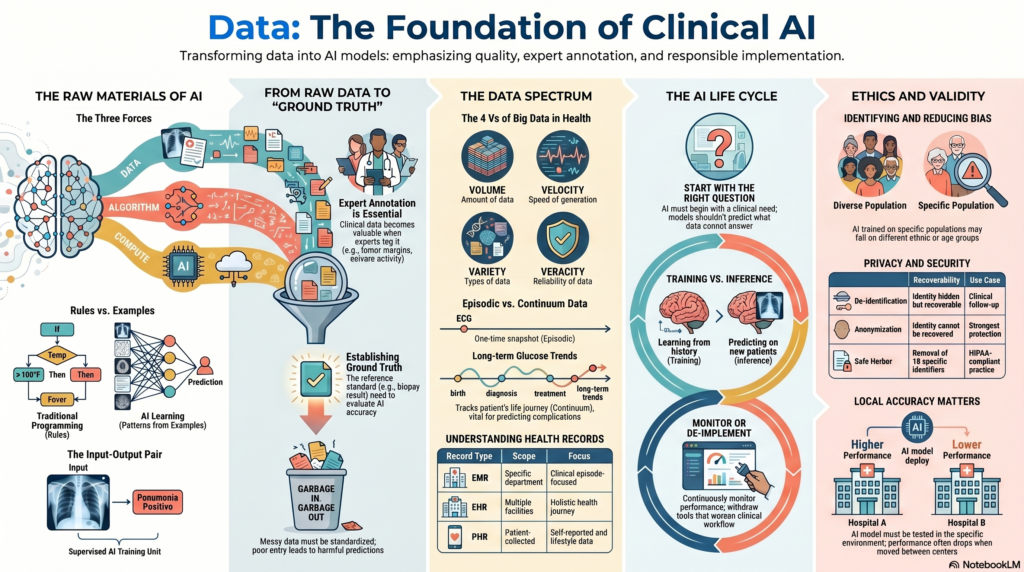 1. Why Data Matters in AI
1. Why Data Matters in AI
The central message of this lecture is simple:
AI is not magic. AI is trained on data.
Traditional programming depends on rules written by humans. AI depends on examples given to the machine.
In traditional programming, we write a rule:
If temperature is above 100°F, classify as fever.
In AI, we provide examples:
| Input | Label |
|---|---|
| 102°F | Fever positive |
| 98°F | Fever negative |
| 101°F | Fever positive |
The AI model then learns the rule from the input-output pairs. This is why data is the foundation of AI.
Clinical example:
If we want AI to identify pneumonia on chest X-ray, we need chest X-ray images and corresponding labels such as “pneumonia positive” or “pneumonia negative.”
2. Data, Algorithm, and Compute
Modern AI has advanced because of three major forces:
- Data
- Algorithms
- Compute power
Data provides the examples.
Algorithms learn patterns from the examples.
Compute power allows large-scale training.
Example:
A deep learning model for mammography may require thousands of mammograms, a neural network algorithm, and GPUs to train efficiently.
Key point:
Among these three, the lecture emphasises that data is foundational. Without good data, even the best algorithm and fastest computer will fail.
3. Input-Output Pair
An input-output pair is the basic unit of supervised AI training.
The input is the data given to the model.
The output is the correct answer or label.
Example in medical imaging:
| Input | Output |
|---|---|
| Chest X-ray | Pneumonia positive |
| Chest X-ray | Pneumonia negative |
| Mammogram | Benign |
| Mammogram | Malignant |
The model learns from many such examples.
Clinical importance:
Existing medical data is usually not naturally available as clean input-output pairs. It has to be curated, cleaned, labelled, and structured before it can be used for AI.
4. Label
A label is the correct answer attached to a data point.
Examples:
- Pneumonia positive
- Pneumonia negative
- Benign lesion
- Malignant lesion
- Diabetic retinopathy present
- Diabetic retinopathy absent
- Depression remission achieved
- Depression remission not achieved
Clinical example:
A chest X-ray alone is not enough to train an AI model. It needs a label telling the model whether pneumonia is present or absent.
Important issue:
Labels must be accurate. If a poorly trained annotator gives wrong labels, the model will learn wrong patterns.
5. Annotation
Annotation is the process of marking or labelling data for AI training.
In medicine, annotation usually requires domain expertise.
Examples:
- Marking a lung nodule on CT
- Labelling a mammogram as benign or malignant
- Identifying tumour margins on pathology slides
- Marking seizure activity on EEG
- Tagging symptoms in electronic health records
In the lecture, the speaker highlighted that expert annotation is essential because data alone has limited value. It becomes valuable when combined with clinical expertise.
Clinical example:
If three radiologists mark a lung nodule differently, the AI team must decide whether to take an average, consensus, or the opinion of the most experienced expert.
6. Ground Truth
Ground Truth is the reference standard or “correct answer” used to train or evaluate an AI model.
Examples:
- Biopsy result for cancer diagnosis
- Expert radiologist consensus for imaging
- Culture result for infection
- Long-term follow-up outcome
- Surgical finding
- Histopathology report
Clinical challenge:
In medicine, ground truth is often not simple. Experts may disagree. Reports may be ambiguous. Biological variation may exist.
Example:
If one radiologist marks a nodule as 8 mm and another marks it as 11 mm, what is the ground truth? This is not merely a technical problem. It is a clinical problem.
7. Training Phase
The Training Phase is the stage where the AI model learns from labelled examples.
Example:
The model is shown thousands of chest X-rays with labels such as “pneumonia positive” and “pneumonia negative.”
The model gradually learns image patterns associated with pneumonia.
Key point:
The model is not memorising one case. It is learning patterns across many cases.
8. Inference Phase
The Inference Phase is when a trained AI model is used on new, unseen data.
Example:
A new chest X-ray is given to the trained model. The model predicts whether pneumonia is present.
This phase may also be called:
- Testing phase
- Prediction phase
- Deployment phase
Clinical importance:
Many biases become visible only during inference. A model may perform well during training but fail when used in real patients from a different population.
9. Prediction
Prediction is the output generated by an AI model for new data.
Examples:
- Pneumonia likely
- Malignancy risk 85%
- High risk of readmission
- Low risk of diabetic retinopathy
- Probability of OPD attendance tomorrow
Clinical warning:
Prediction is not the same as truth. It is a probability or classification generated by a model.
Example:
If an AI model predicts “pneumonia positive,” the doctor still has to correlate with clinical symptoms, examination, oxygen saturation, inflammatory markers, and other findings.
10. Bias
Bias occurs when an AI model gives unfair, inaccurate, or systematically distorted predictions because of problems in the data.
Example from the lecture:
If all chest X-rays used for training are from patients above 75 years, the model may not work well in younger patients.
Other examples:
- Model trained mostly on Western patients may perform poorly in Indian patients.
- Model trained on fair-skin dermatology images may underperform on darker skin.
- Model trained in corporate hospitals may fail in government hospitals.
- Model trained on clean images may fail on lower-quality real-world images.
Clinical message:
Biased data creates biased AI.
11. Data Cleaning
Data Cleaning means correcting, removing, or standardising inaccurate or messy data before using it for AI.
Examples:
- Removing duplicate records
- Correcting wrong entries
- Standardising units
- Handling missing values
- Removing irrelevant artifacts
- Checking inconsistent labels
- De-identifying patient information
Clinical example:
If a radiology report says “not positive for pneumonia,” a simple keyword search for “positive pneumonia” may wrongly classify it as pneumonia positive. Such errors must be cleaned before model training.
12. Data Quality
Data Quality refers to how accurate, complete, consistent, relevant, and usable the data is.
The lecture strongly emphasised that AI model quality depends on data quality.
Examples of poor data quality:
- Missing diagnosis
- Wrong age
- Incorrect label
- Poor image quality
- Inconsistent units
- Unclear clinical notes
- Incomplete follow-up
- Ambiguous ground truth
Memorable line:
Garbage in, garbage out. In healthcare, garbage in may produce a dangerous gospel out.
13. Data Quality Metric
A Data Quality Metric is a standard used to judge whether the data is good enough for the intended question.
The metric depends on the question being asked.
Example 1: OPD count prediction
If the question is, “How many patients will visit OPD tomorrow?”, the key data quality metric is whether patient counts are accurately captured.
Example 2: Diagnostic accuracy
If the question is, “Were all OPD patients correctly diagnosed?”, the data quality metric must include ground truth, diagnosis quality, clinical review, and follow-up.
Key point:
Data quality is not universal. It depends on the clinical question.
14. Asking the Right Question
One of the most important ideas in the lecture is that AI development begins with the right question.
A wrong question cannot be solved by more data or a better algorithm.
Example from the lecture:
If we have only one chest X-ray, the right question may be:
Is this chest X-ray suggestive of pneumonia?
The wrong question may be:
Will this patient develop lung cancer in the future?
The second question requires more information such as smoking history, age, family history, occupational exposure, previous imaging, genetic risk, and follow-up data.
Clinical rule:
Ask only the question that the available data can answer.
15. AI Life Cycle
The AI Life Cycle describes the full process of developing, implementing, monitoring, and updating an AI system.
The lecture described the AI life cycle as one of the most important concepts.
Steps include:
- Identify the clinical need
- Describe the current workflow
- Define the desired target state
- Develop or acquire the AI system
- Implement it in the target setting
- Monitor performance
- Update or de-implement if needed
Clinical example:
If chest X-ray reporting takes 1 hour and the goal is to reduce reporting time to 30 minutes, the AI system should be judged by whether it improves that workflow.
16. Identify the Need
Before building or buying AI, we must ask:
Is there actually a need for AI here?
AI is not required everywhere.
Example:
If a simple checklist solves the problem, AI may be unnecessary.
Clinical example:
If the problem is delayed X-ray reporting, AI may help triage normal and abnormal X-rays. But if the true problem is lack of radiology staff scheduling, AI may not solve the core issue.
17. Existing Workflow
Existing Workflow means how the task is currently done.
Example:
For chest X-ray reporting:
- X-ray is taken
- Image enters PACS
- Radiologist opens the case
- Report is dictated
- Report is verified
- Report reaches clinician
Before adding AI, we need to understand this workflow.
Reason:
An AI model may be accurate but useless if it does not fit into clinical workflow.
18. Target State
The Target State is the desired improvement after using AI.
Examples:
- Reduce report time from 60 minutes to 30 minutes
- Improve detection of early cancer
- Reduce missed nodules
- Decrease documentation burden
- Predict OPD crowding
- Reduce ICU deterioration
- Improve triage efficiency
Important point:
The target state need not always be diagnostic accuracy. It may be time saved, efficiency improved, or workflow optimised.
19. Implementation
Implementation means introducing the AI system into the real clinical environment.
Implementation includes:
- Integration with hospital software
- Training staff
- Setting alert thresholds
- Defining responsibility
- Monitoring errors
- Creating escalation pathways
Clinical example:
A sepsis alert is useful only if it reaches the right clinician at the right time and triggers a clear action.
20. Monitoring Performance
Monitoring Performance means continuously checking whether the AI system is working as expected.
Examples:
- Is report time actually reduced?
- Are false positives increasing?
- Is the model missing cases?
- Is the workflow improving?
- Are clinicians using the tool?
- Is patient outcome improving?
Clinical rule:
AI should not be installed and forgotten. It must be monitored.
21. De-Implementation
De-Implementation means withdrawing an AI system if it does not help or causes harm.
Example from the lecture:
If AI was expected to reduce chest X-ray reporting time from 1 hour to 30 minutes, but instead reporting time increases to 2 hours, it should be de-implemented.
Key point:
Not every AI implementation deserves continuation.
22. Healthcare Continuum
The Healthcare Continuum refers to the full journey of care across prevention, diagnosis, treatment, monitoring, rehabilitation, and long-term follow-up.
AI can be applied across this continuum:
- Preventive health
- Screening
- Diagnosis
- Treatment planning
- Patient monitoring
- Administrative operations
- Drug discovery
- Emergency medicine
- Telemedicine
- Patient care
Clinical example:
A diabetes AI system may include risk prediction, glucose monitoring, complication screening, lifestyle support, medication optimisation, and long-term follow-up.
23. Episodic Data
Episodic Data refers to data collected at a particular time for a specific clinical episode.
Examples:
- One OPD visit
- One admission
- One chest X-ray
- One ECG
- One blood glucose reading
- One discharge summary
Most healthcare data today is episodic.
Clinical limitation:
One fasting glucose value may help diagnose diabetes, but it cannot fully predict long-term complications.
24. Continuum Data
Continuum Data refers to data collected across time, ideally across the patient’s life course.
Examples:
- Immunisation history
- Growth records
- Repeated lab tests
- Wearable data
- Continuous glucose monitoring
- Hospital visits
- Medication history
- Insurance claims
- Long-term outcomes
Clinical importance:
Many meaningful AI questions require continuum data.
Example:
To predict diabetic complications, we need long-term HbA1c trends, blood pressure, renal function, lipid profile, retinal status, adherence, lifestyle, and follow-up—not just one glucose value.
25. Patient, Provider, and Payer Data
The lecture describes three major data holders in healthcare:
- Patient
- Provider
- Payer
Patient data:
Wearables, personal health apps, continuous glucose monitors, self-recorded symptoms.
Provider data:
Hospital records, OPD notes, imaging, lab reports, prescriptions.
Payer data:
Insurance claims, payment data, utilisation patterns.
Clinical point:
Each stakeholder holds a part of the patient’s health story. AI becomes more useful when these data streams can be responsibly integrated.
26. Stakeholder Data
Apart from patients, providers, and payers, other stakeholders also hold healthcare data.
Examples:
- Pharma companies
- Medical device companies
- Diagnostic laboratories
- Research organisations
- Public health agencies
- Government schemes
Example:
Pharma companies may hold clinical trial data and adverse event data. Device companies may hold performance and usage data.
27. Right Intervention, Right Patient, Right Time
This is the “North Star” of data-driven healthcare.
The goal is:
To provide the right intervention to the right patient at the right time.
Example:
Instead of treating all patients with diabetes in the same way, AI may help identify which patient needs aggressive cardiovascular prevention, which needs renal protection, and which needs intensive lifestyle support.
Clinical caution:
This goal requires high-quality, longitudinal, representative, and ethically collected data.
28. Big Data
Big Data refers to very large, complex datasets that cannot be easily handled using traditional methods.
In healthcare, big data may include:
- EHRs
- Imaging
- Genomics
- Wearables
- Claims data
- Pharmacy data
- Lab data
- Public health data
- Mobile health data
The lecture mentions that a 500-bed hospital can generate enormous data daily, with medical imaging contributing a major share by volume.
29. The Four Vs of Big Data
Big data is often described using four Vs:
- Volume — amount of data
- Velocity — speed at which data is generated
- Variety — different types of data
- Veracity — reliability or truthfulness of data
Clinical example:
A continuous glucose monitor produces high-velocity data. Radiology produces high-volume image data. Clinical notes produce high-variety text data. Patient-entered app data may have variable veracity.
30. Data vs Information
The lecture makes an important distinction:
Computers consume data. Humans interpret information.
Data example:
A chest X-ray image file.
Information example:
“This X-ray shows right lower-zone consolidation suggestive of pneumonia.”
Clinical insight:
A doctor converts data into information using context, training, and judgement. AI attempts to learn this transformation from examples.
31. Structured Data
Structured Data is organised data arranged in clear rows and columns.
Examples:
- Age
- Sex
- Blood pressure
- HbA1c
- Creatinine
- Sodium
- Diagnosis code
- Medication dose
Clinical advantage:
Structured data is easier for computers to process.
32. Semi-Structured Data
Semi-Structured Data has some organisation but is not fully standardised.
Examples:
- Electronic health records
- Clinical notes with free-text fields
- Discharge summaries
- Radiology reports
- OPD records
Clinical example:
An EHR may have patient ID and date, but the doctor’s note may be free text. This makes the data semi-structured.
Most provider-generated healthcare data is semi-structured rather than perfectly structured.
33. Unstructured Data
Unstructured Data has no fixed format.
Examples:
- Free-text clinical notes
- Voice recordings
- Patient messages
- Internet literature
- Images without metadata
- Videos
- App-based patient entries
Clinical issue:
Unstructured data often requires processing before it can be used for AI.
34. Metadata
Metadata means data about data.
Example in imaging:
A medical image may contain metadata such as:
- Patient age
- Scanner type
- Imaging protocol
- Pixel spacing
- Resolution
- Date of acquisition
- Body region
Clinical importance:
Metadata helps computers understand the context of the data.
35. EMR
Electronic Medical Record (EMR) refers to digital medical records maintained within a specific department or facility.
Example:
A cardiology department may maintain an EMR for cardiac visits.
Limitation:
The same patient may have separate EMRs in cardiology, neurology, psychiatry, and endocrinology.
36. EHR
Electronic Health Record (EHR) is a broader record that combines data across departments or facilities.
Example:
A patient’s EHR may include cardiology, neurology, psychiatry, lab, radiology, and pharmacy data.
Simple distinction:
| EMR | EHR |
|---|---|
| Department or facility-specific | Broader patient health record |
| Narrower | Wider |
| Clinical episode focused | Health journey focused |
37. PHR
Personal Health Record (PHR) is health data collected or maintained by the patient.
Examples:
- Smartwatch data
- Fitness app data
- CGM data
- Home BP readings
- Self-reported symptoms
- Sleep tracking
Quality issue:
PHR data is often collected in uncontrolled environments, so its quality may be variable.
38. Patient Registry
A Patient Registry is an organised collection of data about patients with a particular condition, treatment, or exposure.
The lecture notes that many AI datasets are conceptually similar to patient registries.
Examples:
- Cancer registry
- Stroke registry
- Diabetes registry
- Rare disease registry
- Psychiatric case registry
- Device outcome registry
Clinical value:
Registries help research, audit, outcome tracking, and AI model development.
39. Retrospective Data
Retrospective Data is data already collected in the past.
Example:
Using hospital records from 2018 to 2025 to train a model for predicting readmission.
Advantages:
- Faster to access
- Less expensive
- Useful for initial model development
Limitations:
- Missing data
- Inconsistent documentation
- Bias
- Poor follow-up
- Unclear ground truth
40. Prospective Data
Prospective Data is collected forward in time for a specific purpose.
Example:
Designing a study where every patient with suspected pneumonia has a standard clinical form, chest X-ray, lab panel, and follow-up.
Advantages:
- Better quality control
- Clearer inclusion criteria
- Better labels
- Standardised collection
Limitation:
It takes more time and planning.
41. Inclusion Criteria
Inclusion Criteria define who is included in a dataset or study.
Example:
Adults above 18 years with chest X-ray-confirmed pneumonia.
Clinical importance:
If inclusion criteria are poorly defined, the AI model may learn from a mixed or inappropriate population.
42. Exclusion Criteria
Exclusion Criteria define who is not included.
Example:
Exclude patients with active lung cancer, post-operative chest X-rays, or poor-quality images.
Clinical importance:
Exclusion criteria prevent confusing or inappropriate data from entering the model.
43. De-Identification
De-Identification means removing personal identifiers from medical data while retaining clinical usefulness.
Examples of identifiers:
- Name
- Phone number
- Address
- Hospital number
- Full face image
- Aadhaar number
- Exact date of birth
The lecture emphasises that healthcare data is usually de-identified rather than fully anonymised, because re-identification may sometimes be needed under controlled conditions.
44. Anonymisation
Anonymisation means removing identifiers so completely that the patient cannot be re-identified.
Difference from de-identification:
| De-identification | Anonymisation |
|---|---|
| Identity hidden but may be recoverable under controlled conditions | Identity cannot be recovered |
| More useful for clinical follow-up | Stronger privacy protection |
| Common in healthcare datasets | Difficult to guarantee fully |
45. Safe Harbor Method
The Safe Harbor Method is a method of de-identification where specific identifiers are removed from health data.
Examples of identifiers removed:
- Names
- Geographic details
- Dates directly related to individual
- Phone numbers
- Email addresses
- Medical record numbers
- Biometric identifiers
- Full-face photographs
This method is used in privacy frameworks such as HIPAA [1].
46. Expert Determination
Expert Determination is a method where a qualified expert assesses whether the risk of re-identification is sufficiently low.
This is useful when data is complex or multimodal.
Examples:
- Text + images + waveform data
- Genomic data
- Rare disease data
- Longitudinal psychiatric data
Clinical importance:
Some data may look de-identified but still be identifiable because of rare combinations of details.
47. Multimodal Data
Multimodal Data means data from multiple types or sources.
Examples:
- Text + image
- Voice + lab data
- ECG + clinical notes
- MRI + cognition scores
- Wearable data + EHR
- Genomics + medication response
Clinical example:
A dementia AI dataset may include cognitive scores, MRI brain, sleep data, medications, family history, and clinical notes.
48. Data Harmonisation
Data Harmonisation means making data from different sources compatible and comparable.
Example:
One hospital records glucose in mg/dL. Another records it in mmol/L. Harmonisation standardises these.
Other examples:
- Standardising diagnosis codes
- Standardising lab units
- Standardising imaging protocols
- Mapping different drug names
- Aligning time stamps
Clinical importance:
Without harmonisation, AI models may learn artificial differences between hospitals rather than true clinical patterns.
49. Local Accuracy
Local Accuracy means an AI model performs well in the place where it was developed but poorly elsewhere.
The lecture notes that many AI algorithms are locally accurate, and performance may drop when moved to another site.
Example:
A model trained on high-quality images from a tertiary centre may perform poorly on images from a smaller centre with different machines.
Clinical message:
An AI model must be tested where it will be used.
50. Trust Metric
A Trust Metric refers to how much confidence we should have in an AI system depending on the clinical stakes.
Example from discussion:
If the AI is predicting OPD count tomorrow, a lower trust threshold may be acceptable.
If the AI is assisting cardiac surgery, the trust threshold must be much higher.
Clinical principle:
The higher the risk, the higher the evidence required.
51. Human Alternative
A Human Alternative means comparing AI output against human expert performance.
Example:
If AI extracts drug names from prescriptions, compare a subset against manual extraction by trained humans.
Why important:
When one AI system is used to prepare data for another AI system, human checking becomes crucial to prevent circular errors.
52. Human Capacity Building
Human Capacity Building means training people to collect, enter, clean, annotate, and validate data properly.
Examples:
- Training nurses to enter structured vitals
- Training radiologists to annotate images consistently
- Training data managers to detect missing values
- Training clinicians to define data quality metrics
- Training researchers to de-identify data properly
Key point:
Better AI begins with better human data practices.
53. Variance
Variance refers to natural or measurement-related variability in data.
Example:
Different doctors may mark slightly different boundaries of the same lung nodule.
Clinical challenge:
Some variance is biological and unavoidable. Some variance comes from poor technique or inconsistent measurement.
54. Biological Variability
Biological Variability means natural variation between patients or within the same patient over time.
Examples:
- Blood pressure varies during the day
- Glucose varies after meals
- Mood symptoms fluctuate
- Sleep changes across weeks
- Tumour appearance varies
- Lab values vary due to biological rhythms
AI implication:
AI models must distinguish true clinical signal from normal biological variation.
55. Bias vs Variance
Bias is systematic error.
Variance is variability.
Example:
If a BP machine always reads 10 mmHg higher, that is bias.
If repeated readings vary widely, that is variance.
Clinical relevance:
Bias may sometimes be corrected. High uncontrolled variance is harder to fix.
56. Gaussian Curve
A Gaussian Curve, or normal distribution, is a bell-shaped distribution.
In data quality checks, numerical data may be plotted to see whether values behave as expected.
Example:
If lab values show extreme tails or strange clustering, it may indicate data entry errors, unit mismatch, or quality problems.
57. Tail Values
Tail Values are extreme values at the ends of a distribution.
Example:
A recorded sodium value of 900 mmol/L is likely a data entry error.
Clinical data cleaning:
Extreme tail values should be reviewed rather than blindly removed, because some may represent real critical illness.
58. Data Entry Error
A Data Entry Error is a mistake made while entering data.
Examples:
- Age entered as 222 years
- Weight entered in pounds instead of kilograms
- Wrong diagnosis code
- Missing decimal point
- Drug dose wrongly typed
- Sex recorded incorrectly
- Wrong patient ID
The lecture notes that errors in healthcare data entry are common and can significantly affect AI model quality.
59. Missing Data
Missing Data means required information is absent.
Examples:
- No diagnosis entered
- Missing lab value
- No follow-up status
- No smoking history
- No medication adherence record
- No outcome data
Clinical issue:
Missing data may not be random. For example, sicker patients may have more tests, while healthier patients may have fewer records.
60. Data Governance
Data Governance refers to the rules, processes, and responsibilities around data collection, access, storage, sharing, quality, security, and use.
Key components:
- Ethics approval
- Consent
- De-identification
- Access control
- Audit trail
- Data quality monitoring
- Data sharing agreements
- Security protocols
Clinical importance:
Healthcare AI without governance can become unsafe, unethical, and legally risky.
61. Ethics Committee Approval
Before using medical data for AI research, researchers generally need approval from an institutional ethics committee.
Why?
- Protect patient privacy
- Ensure responsible data use
- Assess risk-benefit ratio
- Define consent requirements
- Approve de-identification processes
- Monitor ethical compliance
The lecture clearly states that when creating one’s own dataset, ethics board approval is an essential early step.
62. Indian Data for Indian AI
One important discussion point was the need for Indian data.
The reason is simple:
AI models are often locally accurate.
A model trained in one country may not perform well in another because of differences in:
- Genetics
- Environment
- Nutrition
- Disease prevalence
- Pollution exposure
- Health-seeking behaviour
- Documentation style
- Imaging equipment
- Clinical protocols
- Language and culture
Example from discussion:
Cough in Delhi during severe air pollution may have a different background context than cough in a low-pollution setting.
Clinical message:
Indian doctors annotating high-quality Indian data is essential for building useful AI for Indian healthcare.
63. AI as Calculator
A useful analogy from the discussion is that AI can be thought of like a calculator.
A calculator is useful if the user knows:
- What it can do
- What it cannot do
- Whether the output is reasonable
- When not to use it
Similarly, AI is useful only when the doctor understands its boundaries.
Key point:
If you cannot judge the output, you should not blindly use the tool.
64. Boundaries of AI
Boundaries of AI refer to the limits of what a model can safely and validly do.
Example:
A model trained to detect pneumonia on adult chest X-rays should not be used to predict lung cancer risk in children.
Clinical rule:
Use AI only for the task, population, and setting for which it has been validated.
65. Clinical Significance
Clinical Significance means whether a difference matters in patient care.
Example:
If three experts mark a lung nodule slightly differently, the variation may not matter if the diagnosis and treatment remain unchanged.
Why clinicians are needed:
Only domain experts can judge whether a data difference is clinically meaningful.
Simple Clinical Analogy
| Concept | Simple Meaning | Clinical Example |
|---|---|---|
| Data | Raw material | Chest X-ray image |
| Label | Correct answer | Pneumonia positive |
| Annotation | Expert marking | Radiologist marks consolidation |
| Ground truth | Reference standard | CT/biopsy/expert consensus |
| Training | Model learns | Learns from labelled X-rays |
| Inference | Model predicts | New X-ray classified |
| Bias | Systematic error | Model trained only on elderly |
| Data quality | Fitness of data | Correct label, clear image |
| Workflow | Real clinical pathway | X-ray → PACS → report |
| Target state | Desired improvement | Report time reduced |
| De-implementation | Remove failed AI | Tool worsens workflow |
Chest X-ray Example: Asking the Right Question
Available data
One chest X-ray image.
Good AI question
Is there radiological evidence of pneumonia?
This question can be answered because the relevant information may be visible in the X-ray.
Poor AI question
Will this patient develop lung cancer in 10 years?
This cannot be answered from a single X-ray alone. It requires longitudinal data, smoking history, environmental exposure, family history, prior imaging, symptoms, and follow-up.
Lesson
The right AI question must match the available data.
OPD Example: Data Quality Depends on the Question
Question 1
How many patients will attend OPD tomorrow?
Required data:
- Previous OPD counts
- Day of week
- Holiday status
- Seasonal patterns
- Doctor availability
Question 2
Were OPD patients correctly diagnosed?
Required data:
- Clinical notes
- Investigation results
- Expert review
- Follow-up
- Outcome data
- Diagnostic standards
Lesson
The same hospital data may be sufficient for one question and completely insufficient for another.
Final High-Yield Summary
The lecture teaches that AI in healthcare begins not with algorithms, but with data and questions.
Key lessons:
- AI learns from input-output pairs.
- Labels and annotations require clinical expertise.
- Data quality determines model quality.
- Existing healthcare data is often episodic, fragmented, semi-structured, and imperfect.
- Continuum data is needed for long-term prediction and personalised care.
- AI must be integrated into workflow, not simply added as decoration.
- Indian healthcare needs Indian datasets annotated by Indian experts.
- The right question is more important than the most advanced algorithm.
- AI tools must be monitored and removed if they do not improve care.
- The physician must understand the limits of the tool.
Data is the foundation. Expertise gives it meaning. The right question turns it into clinical value.
References
- United States Department of Health and Human Services. Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act Privacy Rule. Washington, DC: HHS; 2012.
- Rajkomar A, Dean J, Kohane I. Machine learning in medicine. New England Journal of Medicine. 2019;380(14):1347-1358.
- Oakden-Rayner L. Exploring large-scale public medical image datasets. Academic Radiology. 2020;27(1):106-112.
- Panch T, Mattie H, Atun R. Artificial intelligence and algorithmic bias: implications for health systems. Journal of Global Health. 2019;9(2):020318.
- Obermeyer Z, Powers B, Vogeli C, Mullainathan S. Dissecting racial bias in an algorithm used to manage the health of populations. Science. 2019;366(6464):447-453.
- Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nature Medicine. 2019;25(1):44-56.
- Kelly CJ, Karthikesalingam A, Suleyman M, Corrado G, King D. Key challenges for delivering clinical impact with artificial intelligence. BMC Medicine. 2019;17:195.
- World Health Organization. Ethics and Governance of Artificial Intelligence for Health: WHO Guidance. Geneva: World Health Organization; 2021.
- Collins GS, Moons KGM, Dhiman P, et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. 2024;385:e078378.
- Wiens J, Saria S, Sendak M, et al. Do no harm: a roadmap for responsible machine learning for health care. Nature Medicine. 2019;25(9):1337-1340.
Related posts:
- Separation-Individuation: Understanding the Foundation of Self-Development in Psychoanalytic Theory
- Who Is Ketamine Therapy For? Understanding Clinical Indications and Patient Suitability
- Comprehensive Clinical Guide: Safe Antidepressant Discontinuation for Psychiatrists
- Neuropsychiatric Manifestations of Temporal Lobe Epilepsy and Their Clinical Management
- ICD-11 Personality Disorders: What Has Changed and Why It Matters in Clinical Practice
- Opioid Dose Equivalents in Clinical Practice: Bridging Heroin Use to Buprenorphine-Based OST