Publicly Available ADHD Databases: Building Blocks for AI-Based Diagnosis and Treatment Prediction
 Attention-Deficit/Hyperactivity Disorder (ADHD) is increasingly being studied through the lens of computational psychiatry, precision diagnosis, neuroimaging, EEG biomarkers, digital phenotyping, and machine learning. Traditionally, ADHD diagnosis has relied on clinical interview, developmental history, rating scales, and impairment across settings. However, modern research is moving toward a more integrated model in which clinical symptoms, neurocognitive performance, EEG signals, MRI/fMRI connectivity, genetics, actigraphy, and longitudinal outcome data are combined to improve diagnostic accuracy and predict treatment response.
Attention-Deficit/Hyperactivity Disorder (ADHD) is increasingly being studied through the lens of computational psychiatry, precision diagnosis, neuroimaging, EEG biomarkers, digital phenotyping, and machine learning. Traditionally, ADHD diagnosis has relied on clinical interview, developmental history, rating scales, and impairment across settings. However, modern research is moving toward a more integrated model in which clinical symptoms, neurocognitive performance, EEG signals, MRI/fMRI connectivity, genetics, actigraphy, and longitudinal outcome data are combined to improve diagnostic accuracy and predict treatment response.
A major reason this field has progressed is the availability of public or controlled-access ADHD datasets. These datasets allow researchers to test algorithms, compare biomarkers, validate models across populations, and develop reproducible methods. However, not all datasets are equally useful. Some are suited for diagnostic classification, some for brain-behaviour correlation, some for developmental trajectory modelling, and only a few are directly useful for treatment-response prediction.
Why Public ADHD Datasets Matter
Public ADHD datasets are important because they allow researchers to move beyond small, single-centre studies. ADHD is heterogeneous: two patients may both meet diagnostic criteria but differ in executive function, emotional regulation, sleep, comorbidity, medication response, and functional impairment. This makes ADHD an ideal condition for multimodal data science.
Public datasets help answer questions such as:
- Can EEG distinguish ADHD from typical development?
- Are there reproducible resting-state fMRI connectivity patterns in ADHD?
- Can machine learning predict ADHD diagnosis from brain imaging?
- Can digital activity data identify hyperactivity or restlessness?
- Can baseline cognition or neural markers predict stimulant response?
- Can large cohorts reveal ADHD subtypes or developmental trajectories?
At present, the strongest public resources are for diagnostic prediction. Public datasets specifically designed for medication-response prediction remain limited.
Major Publicly Available ADHD Datasets
1. ADHD-200 Dataset
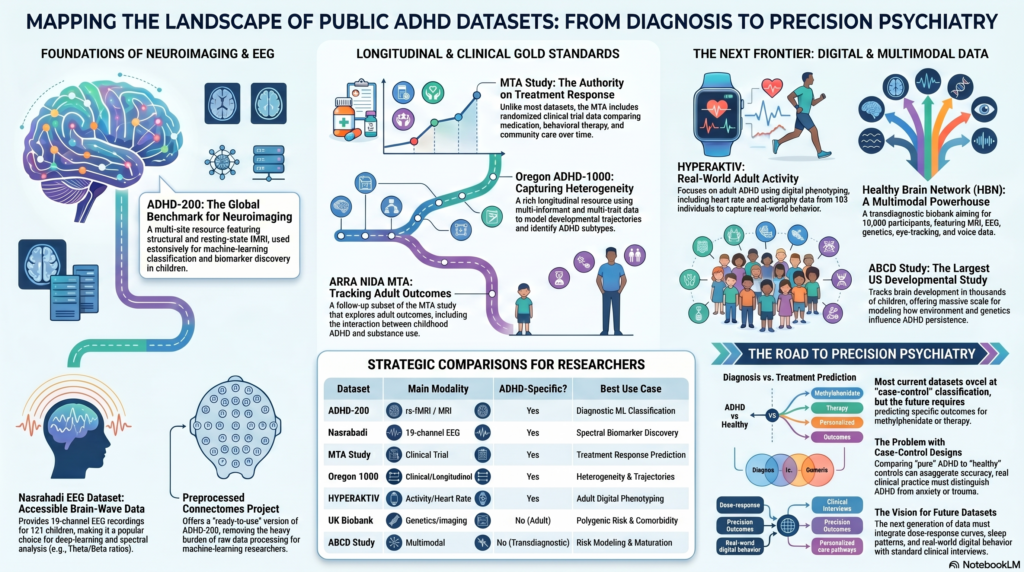
The ADHD-200 dataset is one of the most influential public datasets in ADHD neuroimaging research. It was created through the International Neuroimaging Data-sharing Initiative and includes structural MRI, resting-state functional MRI, and phenotypic data from children and adolescents with ADHD and typically developing controls. The dataset was also used in the ADHD-200 Global Competition, which encouraged researchers to develop algorithms for ADHD classification from neuroimaging data.
The ADHD-200 dataset became important because it provided a large, multi-site resource at a time when most ADHD neuroimaging studies were small and underpowered. It has been used to study resting-state functional connectivity, regional homogeneity, fractional amplitude of low-frequency fluctuations, structural brain differences, and machine-learning classification models. A 2023 review on machine learning in ADHD notes that ADHD-200 has supported numerous studies using resting-state fMRI features such as ReHo, fALFF, power spectra, functional connectivity, and ROI-level networks.
Strengths
- Large-scale neuroimaging dataset.
- Multi-site design.
- Includes ADHD and typically developing controls.
- Useful for fMRI-based biomarker discovery.
- Frequently used benchmark dataset in machine-learning studies.
Limitations
- Site heterogeneity can affect model generalisability.
- Mostly useful for diagnosis, not treatment-response prediction.
- Imaging biomarkers alone have not yet reached clinical diagnostic reliability.
- Phenotypic depth is limited compared with newer cohorts.
Best use
ADHD-200 is best suited for studies on resting-state fMRI connectivity, structural MRI markers, diagnostic classification, and reproducibility of neuroimaging biomarkers.
2. ADHD-200 Preprocessed Dataset
The ADHD-200 Preprocessed dataset is a derivative of ADHD-200 in which imaging data were preprocessed using standard neuroimaging pipelines. The Preprocessed Connectomes Project describes ADHD-200 as a collaboration of eight international imaging sites sharing neuroimaging data from children and adolescents with ADHD and controls.
This dataset is especially useful for researchers who do not want to begin from raw imaging files. It allows faster development of machine-learning pipelines, particularly for functional connectivity analysis.
Strengths
- Reduces preprocessing burden.
- Allows comparison across preprocessing pipelines.
- Useful for beginners in neuroimaging machine learning.
Limitations
- Results may depend strongly on preprocessing choices.
- Not ideal if the researcher wants full control over raw-data processing.
- Carries the same diagnostic and phenotypic limitations as ADHD-200.
Best use
Useful for functional connectivity modelling, graph-theory analysis, and machine-learning benchmarking.
3. Nasrabadi et al. EEG Dataset
The Nasrabadi et al. EEG dataset is one of the most widely used open EEG datasets for ADHD classification. It contains 19-channel EEG recordings from 61 children with ADHD and 60 healthy controls. The Kaggle version describes it as an open-access 19-channel EEG dataset of ADHD and healthy children.
Recent EEG-based ADHD studies continue to use this dataset because it provides relatively clean case-control data. One recent Frontiers study describes the dataset as including 61 children with ADHD and 60 healthy children aged 7–12 years; the ADHD group had been diagnosed using DSM-IV criteria and had received methylphenidate treatment for up to six months.
This dataset has been used for spectral analysis, theta/beta ratio studies, entropy features, nonlinear signal analysis, convolutional neural networks, graph convolutional networks, and automated ADHD classification.
Strengths
- Easy access.
- EEG modality is clinically attractive because it is cheaper than MRI.
- Good for proof-of-concept classification.
- Commonly used in deep-learning studies.
Limitations
- Small sample size.
- Paediatric-only dataset.
- Case-control structure may exaggerate classification performance.
- Medication history may confound EEG findings.
- Limited longitudinal or treatment-outcome data.
Best use
Useful for EEG-based ADHD classification, spectral biomarkers, theta/beta ratio studies, and deep-learning model development.
4. Oregon ADHD-1000
The Oregon ADHD-1000 is a newer and richer ADHD-focused longitudinal dataset. It was designed as a public resource with a case-control structure and includes multi-method, multi-measure, multi-informant, multi-trait data.
The NIMH Data Archive description notes that the Oregon ADHD-1000 is a longitudinal resource enriched for clinical cases and multiple levels of analysis, using a case-control design for ADHD and non-ADHD youth.
This dataset is particularly important because it moves beyond a simple “ADHD vs control” design. It includes richer behavioural, cognitive, developmental, and clinical data, making it more suitable for identifying subgroups, developmental pathways, and predictors of impairment.
Strengths
- Longitudinal design.
- ADHD-focused.
- Multi-informant and multi-measure.
- Better suited for heterogeneity research than simple case-control datasets.
- Useful for studying developmental trajectories.
Limitations
- Controlled access may be required.
- Not as widely used as ADHD-200 or Nasrabadi EEG.
- Requires more complex modelling.
Best use
Useful for ADHD heterogeneity, developmental modelling, subtype discovery, functional impairment prediction, and longitudinal risk modelling.
5. Multimodal Treatment Study of ADHD — MTA Dataset
The Multimodal Treatment Study of Children with ADHD, commonly called the MTA Study, is one of the most important datasets for treatment-response research in ADHD. It was a large, multi-site trial designed to compare leading ADHD treatments, including medication management, behavioural therapy, combined treatment, and community care. The NIMH describes the MTA as a multi-site study designed to evaluate leading treatments for ADHD, with primary results published in 1999 and follow-up data continuing to be published.
The MTA is particularly valuable because, unlike many public ADHD datasets, it directly includes treatment assignment and clinical outcomes. The NIMH Data Archive also hosts MTA-related collections, including continuation studies that tracked persistence of intervention-related effects as participants matured into adolescence.
Strengths
- One of the strongest ADHD treatment datasets.
- Randomised clinical trial design.
- Includes medication, behavioural therapy, combined treatment, and community care arms.
- Longitudinal follow-up.
- Useful for treatment-response and outcome prediction.
Limitations
- Historical cohort.
- Treatment protocols may not fully reflect current practice.
- Data access may require approval.
- Imaging and digital biomarker data are limited compared with modern cohorts.
Best use
Useful for treatment-response prediction, comparative effectiveness research, long-term ADHD outcome modelling, and predictors of medication vs behavioural response.
6. ARRA NIDA MTA Neuroimaging Dataset
A related resource is the ARRA NIDA MTA Neuroimaging Study, which includes a subset of participants from the original MTA follow-up. The dataset includes individuals with and without childhood ADHD and was designed partly to examine the effects of cannabis use among adults with a childhood diagnosis of ADHD.
Strengths
- Links adult outcomes to childhood ADHD history.
- Adds neuroimaging to an important longitudinal ADHD cohort.
- Useful for studying long-term neurodevelopmental consequences.
Limitations
- Subset of the original MTA sample.
- Not primarily designed for ADHD medication-response prediction.
- Cannabis exposure may complicate interpretation.
Best use
Useful for adult outcomes of childhood ADHD, neuroimaging follow-up, and ADHD–substance-use interaction research.
7. HYPERAKTIV Dataset
The HYPERAKTIV dataset is a public dataset containing activity and heart-rate data from adult patients diagnosed with ADHD and clinical controls. The official dataset page describes it as a public dataset containing health, activity, and heart-rate data from adult ADHD patients.
The GitHub repository describes the dataset as including 51 patients with ADHD and 52 clinical controls, along with patient attributes such as age, sex, mental-state information, and results from a computerized neuropsychological test.
This dataset is important because it reflects the growing field of digital phenotyping. Instead of relying only on symptom checklists or brain scans, digital datasets can capture real-world activity patterns, physiological arousal, sleep-wake rhythms, and behavioural variability.
Strengths
- Adult ADHD dataset.
- Includes wearable-like activity and heart-rate data.
- Useful for digital biomarker research.
- Includes clinical controls rather than only healthy controls.
Limitations
- Small sample size.
- Not a medication-response dataset.
- Activity data may be influenced by lifestyle, work, sleep, and comorbidity.
- Requires careful feature engineering.
Best use
Useful for digital phenotyping, activity-based ADHD classification, adult ADHD modelling, and real-world behavioural biomarker research.
8. Healthy Brain Network Dataset
The Healthy Brain Network is a large open-science initiative by the Child Mind Institute. It collects psychiatric, behavioural, cognitive, lifestyle, neuroimaging, EEG, eye-tracking, voice, video, genetics, and actigraphy data from children and adolescents. A Scientific Data paper describes HBN as an open resource for transdiagnostic research in paediatric mental health and notes that the biobank was designed to collect data from 10,000 participants aged 5–21 years.
The Child Mind Institute states that HBN is building one of the largest datasets of the developing brain and sharing de-identified data with the global scientific community to improve diagnosis and treatment from an objective biological perspective.
Strengths
- Very rich multimodal data.
- Includes clinical, cognitive, EEG, MRI, actigraphy, genetics, voice, and video.
- Transdiagnostic design reflects real-world comorbidity.
- Useful for ADHD, anxiety, autism, learning disorders, and broader developmental psychopathology.
Limitations
- Not ADHD-specific.
- Requires careful case definition.
- Comorbidity may complicate ADHD-only modelling.
- Large multimodal data require advanced computational expertise.
Best use
Useful for multimodal ADHD modelling, transdiagnostic biomarkers, comorbidity analysis, EEG/fMRI integration, and developmental psychiatry research.
9. HBN-EEG Dataset
A more specific derivative is the Healthy Brain Network EEG dataset, also known as HBN-EEG. It is described as a curated collection of high-resolution EEG data from over 3,000 participants aged 5–21 years, formatted in BIDS and annotated with Hierarchical Event Descriptors.
This is potentially one of the most promising EEG resources for child and adolescent mental-health research because of its size and standardised formatting.
Strengths
- Large EEG dataset.
- BIDS-formatted.
- Includes paediatric and adolescent age range.
- Useful for large-scale EEG machine learning.
- More scalable than small ADHD-only EEG datasets.
Limitations
- Transdiagnostic rather than ADHD-only.
- Diagnostic labels and comorbidities require careful handling.
- EEG preprocessing choices remain critical.
Best use
Useful for large-scale paediatric EEG modelling, ADHD vs non-ADHD classification, transdiagnostic electrophysiology, and EEG-based biomarker development.
10. ABCD Study Dataset
The Adolescent Brain Cognitive Development Study, or ABCD Study, is the largest long-term study of brain development and child health in the United States. It includes neuroimaging, cognitive testing, mental-health measures, substance-use variables, environmental data, genetics, and longitudinal follow-up.
ABCD is not an ADHD-specific dataset, but it is highly valuable for ADHD research because it contains ADHD symptom measures, diagnostic variables, cognitive data, brain imaging, environmental exposures, family history, and longitudinal developmental outcomes. The NIMH Data Archive states that ABCD data releases are available through the NIH Brain Development Cohorts Data Hub.
Strengths
- Very large sample.
- Longitudinal design.
- Multimodal data.
- Captures development, environment, family, cognition, and mental health.
- Useful for risk modelling and developmental trajectories.
Limitations
- Not ADHD-specific.
- ADHD definitions may vary depending on measures used.
- Requires controlled access.
- Analysis can be computationally intensive.
Best use
Useful for developmental ADHD trajectories, environmental risk, brain maturation, comorbidity, cognitive outcomes, and prediction of persistence/remission.
11. Philadelphia Neurodevelopmental Cohort
The Philadelphia Neurodevelopmental Cohort, or PNC, is a large neurodevelopmental dataset focused on brain-behaviour relationships and genetics. It includes participants from the greater Philadelphia area and contains clinical, cognitive, genomic, and neuroimaging data. The University of Pennsylvania notes that non-identifying PNC data are made publicly available to qualified investigators through dbGaP.
A major publication describes PNC data as publicly available through the database of Genotypes and Phenotypes and highlights its use for studying neurodevelopmental phenotypes.
Strengths
- Large neurodevelopmental cohort.
- Includes cognition, psychopathology, genetics, and neuroimaging.
- Useful for studying ADHD traits dimensionally.
- Good for gene-brain-behaviour modelling.
Limitations
- Not ADHD-specific.
- Access may require dbGaP approval.
- ADHD phenotyping may be less detailed than in ADHD-focused clinical cohorts.
Best use
Useful for dimensional ADHD trait analysis, cognitive control, executive function, genetics, and neurodevelopmental risk modelling.
12. NIMH Data Archive ADHD Collections
The NIMH Data Archive, or NDA, is not a single dataset but a major repository that hosts many mental-health datasets, including ADHD-related collections. The NDA states that it makes human-subjects data from hundreds of research projects available to the research community.
For ADHD researchers, the NDA is important because it includes collections such as MTA, Oregon ADHD-1000, ABCD, and other developmental psychiatry datasets. Many NDA datasets require application and institutional approval before individual-level data can be downloaded.
Strengths
- Central hub for many ADHD and developmental psychiatry datasets.
- Includes longitudinal, clinical, imaging, and behavioural data.
- Supports reproducible research.
Limitations
- Controlled access.
- Requires data-use agreements.
- Datasets vary widely in quality, modality, and ADHD relevance.
Best use
Useful for systematic dataset discovery, secondary analysis, replication studies, and large-scale ADHD research.
13. UK Biobank
The UK Biobank is not an ADHD-specific dataset, but it is widely used for adult population-level research involving genetics, health records, cognition, imaging, and psychiatric traits. It has been used in ADHD polygenic-risk studies, including work examining how common genetic variation associated with ADHD relates to broader traits and disorders.
Strengths
- Very large adult cohort.
- Genetics, imaging, lifestyle, and health data.
- Useful for ADHD polygenic risk and adult outcomes.
- Strong for comorbidity and epidemiological modelling.
Limitations
- ADHD cases may be under-ascertained.
- Not designed as a clinical ADHD cohort.
- Mostly adult and middle-aged/older population.
- Diagnostic granularity may be limited.
Best use
Useful for ADHD polygenic risk, adult ADHD correlates, comorbidity, cognition, substance use, obesity, and population psychiatry.
14. OpenNeuro ADHD-Relevant Datasets
OpenNeuro is a platform for sharing neuroimaging datasets, including MRI, MEG, EEG, iEEG, ECoG, ASL, and PET data. Some ADHD-relevant datasets, including HBN EEG releases, are available through OpenNeuro.
Strengths
- BIDS-format datasets.
- Open access to neuroimaging and electrophysiology data.
- Useful for reproducible pipelines.
Limitations
- ADHD-specific datasets must be identified individually.
- Clinical phenotyping varies.
- Dataset quality and documentation vary.
Best use
Useful for neuroimaging pipeline development, EEG/MRI reproducibility, and open-science ADHD projects.
Summary Table: Public ADHD and ADHD-Relevant Datasets
| Dataset | Main Modality | Population | ADHD-Specific? | Best Use |
|---|---|---|---|---|
| ADHD-200 | rs-fMRI, structural MRI, phenotype | Children/adolescents | Yes | Neuroimaging-based ADHD classification |
| ADHD-200 Preprocessed | Preprocessed MRI/fMRI | Children/adolescents | Yes | Functional-connectivity ML pipelines |
| Nasrabadi EEG Dataset | 19-channel EEG | Children | Yes | EEG classification, spectral biomarkers |
| Oregon ADHD-1000 | Clinical, behavioural, cognitive, longitudinal | Youth | Yes | ADHD heterogeneity and trajectories |
| MTA Study | Clinical trial, treatment outcomes | Children with ADHD | Yes | Treatment-response prediction |
| ARRA NIDA MTA Neuroimaging | MRI/fMRI, adult follow-up | Adults with/without childhood ADHD | Partly | Long-term ADHD outcomes |
| HYPERAKTIV | Activity, heart rate, neuropsychology | Adults | Yes | Digital phenotyping |
| Healthy Brain Network | MRI, EEG, actigraphy, genetics, clinical | Children/adolescents | No, transdiagnostic | Multimodal developmental psychiatry |
| HBN-EEG | High-resolution EEG | Children/adolescents | No, transdiagnostic | Large-scale EEG modelling |
| ABCD Study | MRI, cognition, behaviour, genetics, environment | Children/adolescents | No, but ADHD variables available | Developmental trajectory modelling |
| PNC | Imaging, cognition, genetics, psychopathology | Youth | No, but ADHD traits available | Gene-brain-behaviour studies |
| NIMH Data Archive | Repository of multiple datasets | Mixed | Contains ADHD collections | Dataset discovery and secondary analysis |
| UK Biobank | Genetics, imaging, health records | Adults | No | Adult ADHD genetics and comorbidity |
| OpenNeuro ADHD-relevant datasets | MRI, EEG, MEG, other neurodata | Mixed | Varies | Open neuroimaging pipelines |
Diagnostic Prediction vs Treatment-Response Prediction
A crucial distinction must be made between datasets for diagnosing ADHD and datasets for predicting treatment response.
Most public ADHD datasets are diagnostic or observational. They ask:
“Can we distinguish ADHD from controls?”
Fewer datasets ask:
“Which patient will respond best to methylphenidate, atomoxetine, behavioural therapy, neurofeedback, or combined care?”
For treatment-response prediction, the ideal dataset should include:
- baseline symptom severity;
- ADHD subtype or presentation;
- comorbidities;
- medication exposure;
- dose and duration;
- adherence;
- side effects;
- repeated rating-scale scores;
- functional outcomes;
- sleep and activity data;
- cognition;
- EEG or neuroimaging markers;
- long-term follow-up.
The MTA dataset remains one of the most important resources for treatment-related ADHD research because it directly studied medication, behavioural treatment, combined treatment, and community care. However, modern multimodal treatment-response datasets integrating EEG, CPT, sleep, digital behaviour, genetics, and medication trajectories are still scarce.
Why Current Datasets Are Still Not Enough
Despite the growth of public ADHD databases, several limitations remain.
1. ADHD is clinically heterogeneous
ADHD is not a single biological entity. Patients differ in inattention, hyperactivity, impulsivity, emotional dysregulation, executive dysfunction, sleep problems, sensory issues, learning difficulties, anxiety, depression, substance use, and autism traits. A model trained on a narrow case-control dataset may perform poorly in real-world clinics.
2. Case-control designs may exaggerate accuracy
Many machine-learning studies compare clear ADHD cases with healthy controls. This is easier than real clinical practice, where the differential diagnosis includes anxiety, sleep deprivation, trauma, bipolar disorder, substance use, autism, learning disorder, depression, and personality-related emotional dysregulation.
3. Site effects are a major issue
In neuroimaging datasets such as ADHD-200, scanner differences, site protocols, age distributions, and recruitment methods can influence model performance.
4. Treatment data are limited
Most datasets do not contain enough structured information on medication choice, dose, adherence, adverse effects, and response over time.
5. Adult ADHD remains underrepresented
Many major datasets focus on children and adolescents. Adult ADHD datasets, particularly with multimodal biomarkers, remain relatively limited. HYPERAKTIV is valuable here because it focuses on adult ADHD digital phenotyping.
The Future: Toward Precision Psychiatry in ADHD
The next generation of ADHD datasets should be longitudinal, multimodal, clinically realistic, and treatment-aware. The most useful future database would combine:
- structured diagnostic interview;
- rating scales such as ADHD-RS, ASRS, SNAP-IV, Vanderbilt, Conners;
- CPT performance;
- EEG/QEEG;
- sleep and actigraphy;
- medication history;
- dose-response curves;
- adverse effects;
- academic or occupational functioning;
- emotional dysregulation measures;
- comorbidity mapping;
- family history;
- genetics;
- real-world digital behaviour;
- follow-up outcomes.
This would allow models to move from simple classification to clinically meaningful questions:
- Who needs medication urgently?
- Who may respond to behavioural therapy alone?
- Who is likely to develop stimulant side effects?
- Who has ADHD plus sleep dysregulation?
- Who has ADHD plus emotional dysregulation?
- Who may need combined care?
- Who is likely to have persistent adult ADHD?
Conclusion
Public ADHD datasets have played a major role in shifting ADHD research from purely symptom-based description toward data-driven, multimodal, and biomarker-informed psychiatry. ADHD-200 helped establish open neuroimaging research in ADHD. The Nasrabadi EEG dataset made EEG-based classification widely accessible. The MTA dataset remains central for treatment-response research. Oregon ADHD-1000 adds longitudinal clinical richness. HYPERAKTIV introduces real-world activity and heart-rate data. Healthy Brain Network, ABCD, PNC, UK Biobank, and OpenNeuro expand the field into developmental, genetic, and transdiagnostic modelling.
The future of ADHD research will not depend on one biomarker alone. It will depend on integrating clinical wisdom with objective signals: symptoms, cognition, EEG, sleep, digital behaviour, family context, comorbidity, and treatment outcomes. That is where precision psychiatry in ADHD is likely to emerge.
Related posts:
- Adult ADHD: Assessment, Diagnosis, Differential Diagnosis, and Treatment
- fNIRS + HRV + EEG: A Match Made in Heaven for ADHD Diagnosis & Treatment — Powered by Muse S Athena
- Couples Therapy: Strengthening Relationships and Building Lasting Connections
- Life Skills Training in Autism: Building Independence, One Step at a Time
- Employment and Autism: Building Meaningful Careers for Autistic Adults
- Behavior Therapy in Autism: Building Skills and Reducing Challenges